
Harness as a Service
The era of HaaS is here.

Everyone is talking about agents lately, and for good reason. LLMs have gotten good at handling longer, messier tasks on their own. METR has the clearest data on this. The length of tasks these models can finish at 50% success keeps doubling, roughly every seven months, with Anthropic’s Fable 5 model being capable of working for 16 hours.
A newer, related, term that is much discussed is “harness.” In short, a harness is everything around a model that lets it actually go do work. Add an LLM + a harness, and you have an agent. But it is also much more than that, let’s dive in!
What is a harness?
The model generates tokens. The harness is everything else. The tool loop. File system access. Permission model. Context management. The sandbox where any code the model writes actually runs.
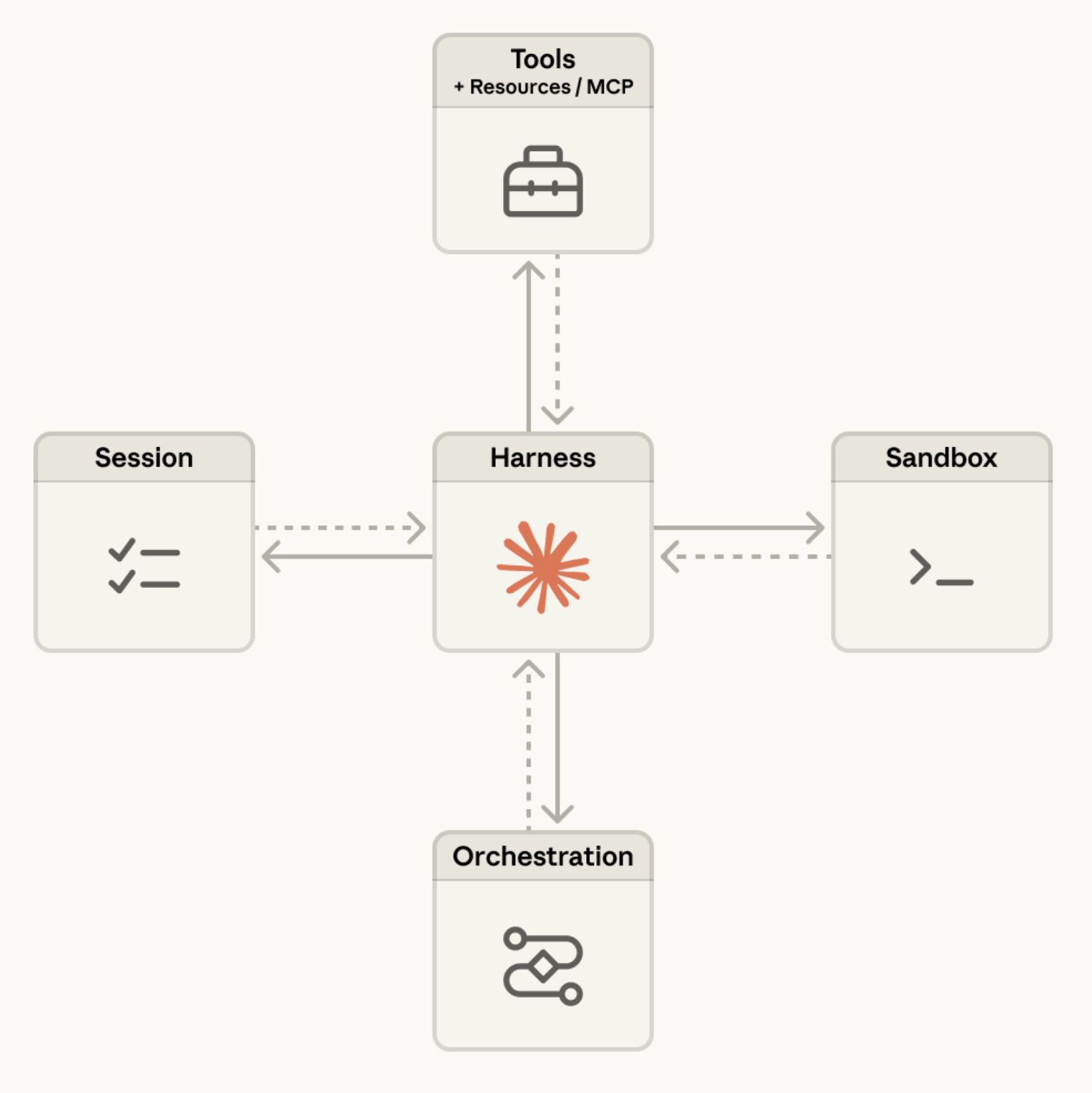
Claude Code is the harness that wraps Anthropic models like Sonnet and Opus. Codex is the harness for OpenAI’s models. Cursor and Google’s Antigravity are harnesses too.
Anthropic and OpenAI both ship SDKs that let you build on top of their harnesses. The Claude Agent SDK is the same harness that powers Claude Code, just packaged as a library. Same idea with the Codex SDK.
How much does the harness actually matter in relation to model performance? It’s measurable. Matt Maher’s open-source planning benchmark hands an agent a Product Requirement Document (PRD) and measures how much of it lands in the implementation plan and the final build. He ran every major model through every major harness.

Edwin Arbus summed it up: Cursor boosted model performance by 11% on average. Same Opus (4.6) model in Cursor vs Claude Code: 77% to 93%. A 16-point swing from the harness alone. So should we all be using Anthropic models in Cursor instead of Claude Code?
I was interested to see if this benchmark held or not with newer models. So I re-ran the benchmark and the delta completely collapsed.
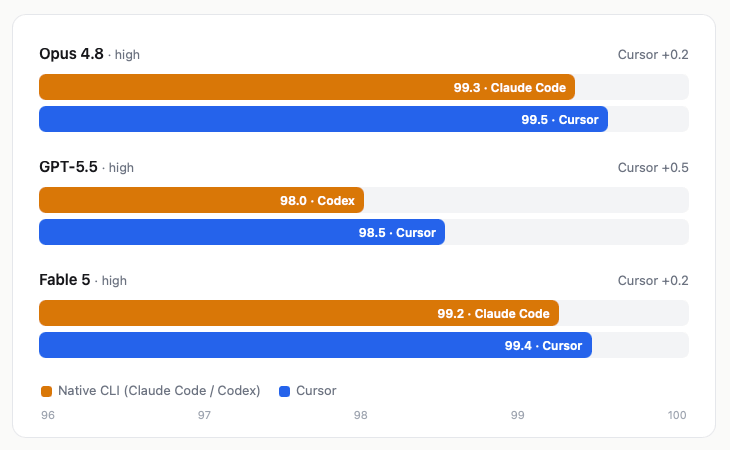
Opus 4.8 in Claude Code vs Cursor: 0.2 points apart
GPT-5.5 in Codex vs Cursor: 0.5 points
Fable 5 in Claude Code vs Cursor: 0.2 points
This can mean a few things:
The top three harnesses are all similar quality for the main coding loop. The benchmark only tests vanilla coding tasks, so it doesn't capture more complex features like Claude Code's Workflows (delegating to hundreds of subagents) or Dreaming (self-improving agents).
The models are getting better so the harness matters less (but you still need one)
The benchmark is clearly saturated and no longer tests how performant the harnesses are because the task itself is too easy. This is where I land.
From just API requests to agent harnesses
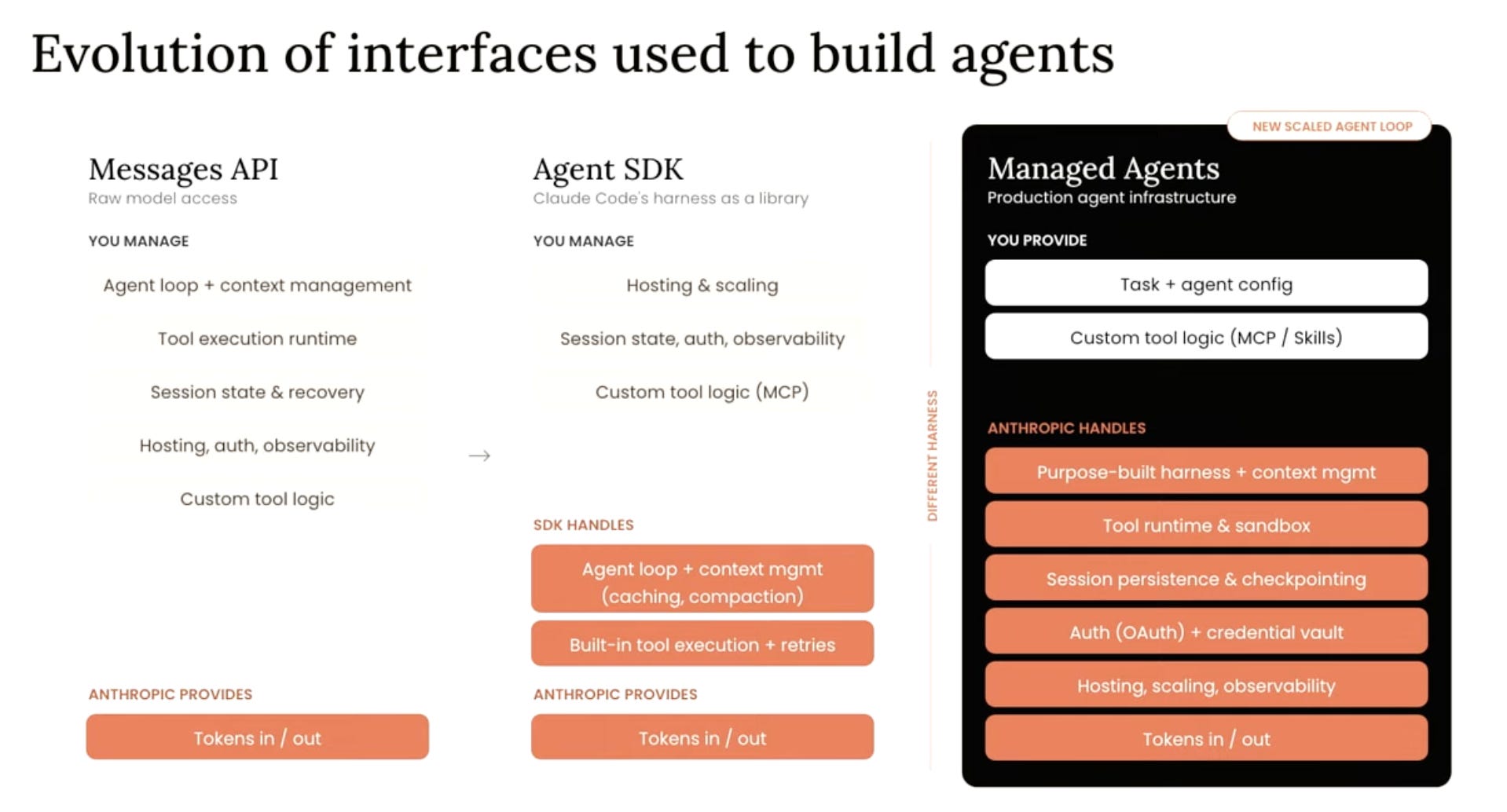
For most of 2023 and 2024, the way you built on top of OpenAI/Anthropic’s models was you bought tokens via the API. You would send a request (a prompt) and get an output and you were charged by the token.
That changed once agents got real. I like to think of Claude Code as the first really effective and widely adopted agent. Once you’re running a loop, dispatching tools, managing state across turns, and recovering from errors, you’re not just making API calls. You’re running a full harness. (We learned this firsthand building Converge.)
Anthropic narrates this exact arc via the image above.
In 2023 it was the Messages API, where developers built every primitive themselves. Then came the Claude Agent SDK, a harness packaged as a library, but you still managed hosting and scaling. Now, just as of a few months ago, Anthropic launched Claude Managed Agents, where Anthropic runs the harness for you (hosting, scaling, observability).
From raw API requests to a harness library to a managed harness. At each step, the lab takes on more of what used to be the job of the developer. And this is a good thing!
While building out our coding agent, Converge, we used Vercel’s AI SDK, which is similar to the products from OpenAI and Anthropic. We had a ton of issues with it, but it was still valuable in managing a lot of the core agent loop so we could focus on what made our agents differentiated and specific to us (tool descriptions, system prompts, the surrounding tech). This is where teams need to focus. This is where the differentiated value lives.
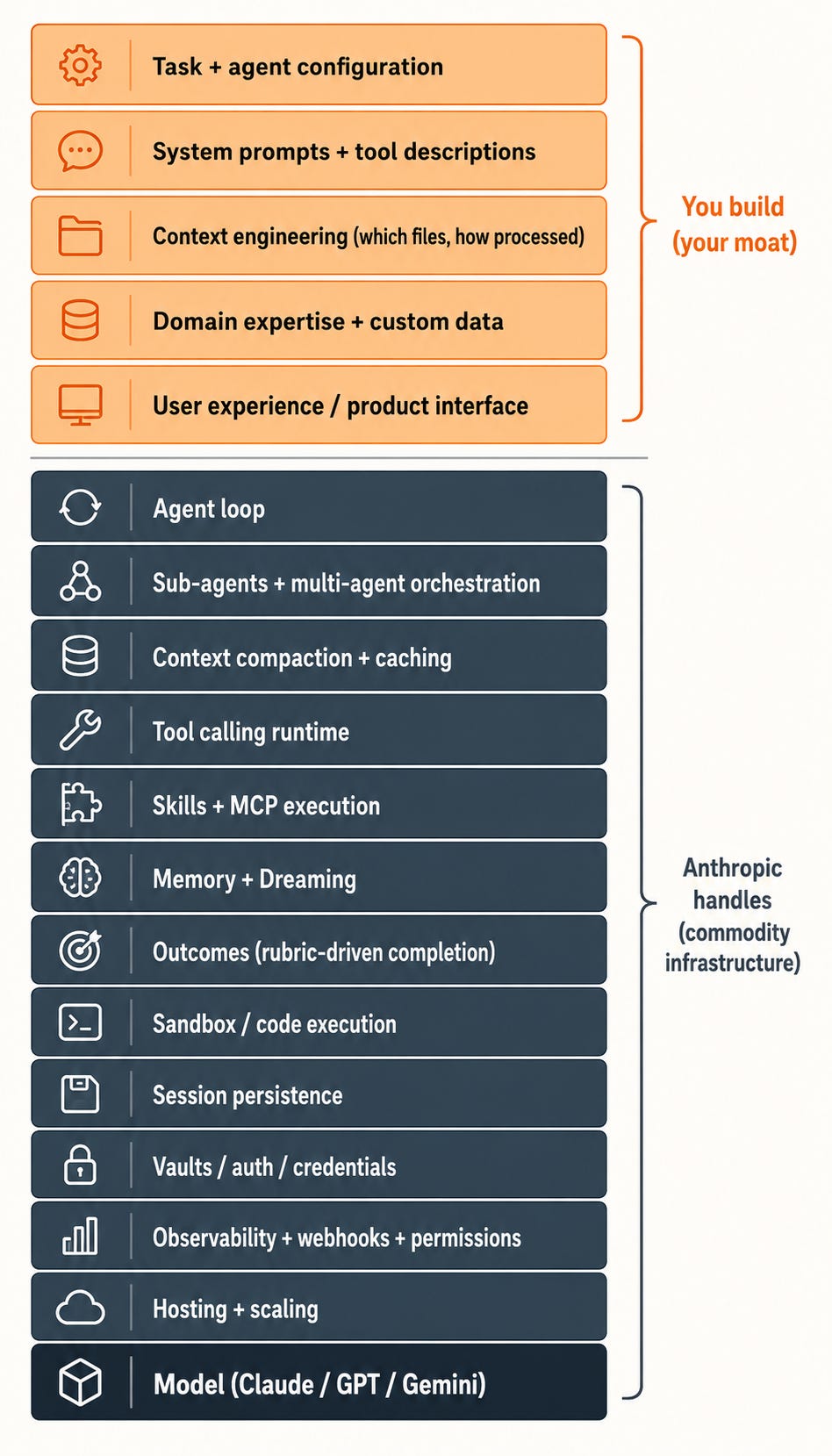
Why you shouldn’t build your own harness
There was a window in ~2024/2025 where building your own harness made sense. The labs hadn’t shipped good ones. There were solid open-source options from Vercel and CrewAI (remember CrewAI?), but a lot of teams rolled their own context management, tool dispatcher, retry logic, sandboxing.
That time is over.
The labs (and Cursor) have full-time teams shipping new harness features all the time. As mentioned before, just in the past few weeks Anthropic has launched Workflows (delegate to hundreds of subagents), Dreaming (agents that reflect and improve automatically), observability, and sandbox isolation. Replicating that in-house, especially as a startup, is just too much work. Especially when the alternative is that the ability just appears for your agent.
The best harnesses are coming from companies that also build the models.
Anthropic → Claude Code (Claude Agent SDK)
OpenAI → Codex
Cursor → Cursor SDK
What’s great about this is that the harness and model get co-optimized. That feedback loop doesn’t exist for third-party harnesses that only see the API surface.
For example (from this Anthropic demo video), Anthropic shipped mitigations in their harness to push back on a Sonnet 4.5 behavior they called “context anxiety.” Claude was wrapping up tasks early when it thought it was running out of context, even when it wasn’t. They wrote special code in the harness to fix that. Then Opus 4.5 came out and the behavior was gone, so they updated the harness accordingly.
Harnesses need to update as new models are released, and it makes sense that the companies building the models will be the best at this optimization.
We hit this firsthand when building Converge. We picked the Vercel AI SDK because we wanted multi-model support. What’s kind of funny about that is that we only ever shipped Anthropic models because they were the only ones that passed our internal benchmarks.
So we paid the full cost of a model-agnostic framework, a lot of custom code especially around tool management, multiple system prompts since different model providers require different prompting strategies, and got none of the benefits. If I were starting today I’d standardize on the Claude Agent SDK from day one. So that every harness improvement Anthropic shipped would have come to us for free.
Wrapping up
What’s interesting is with Managed Agents, Anthropic is now moving into the infrastructure layer for running your agents as well. Where in the stack does the expansion go next?